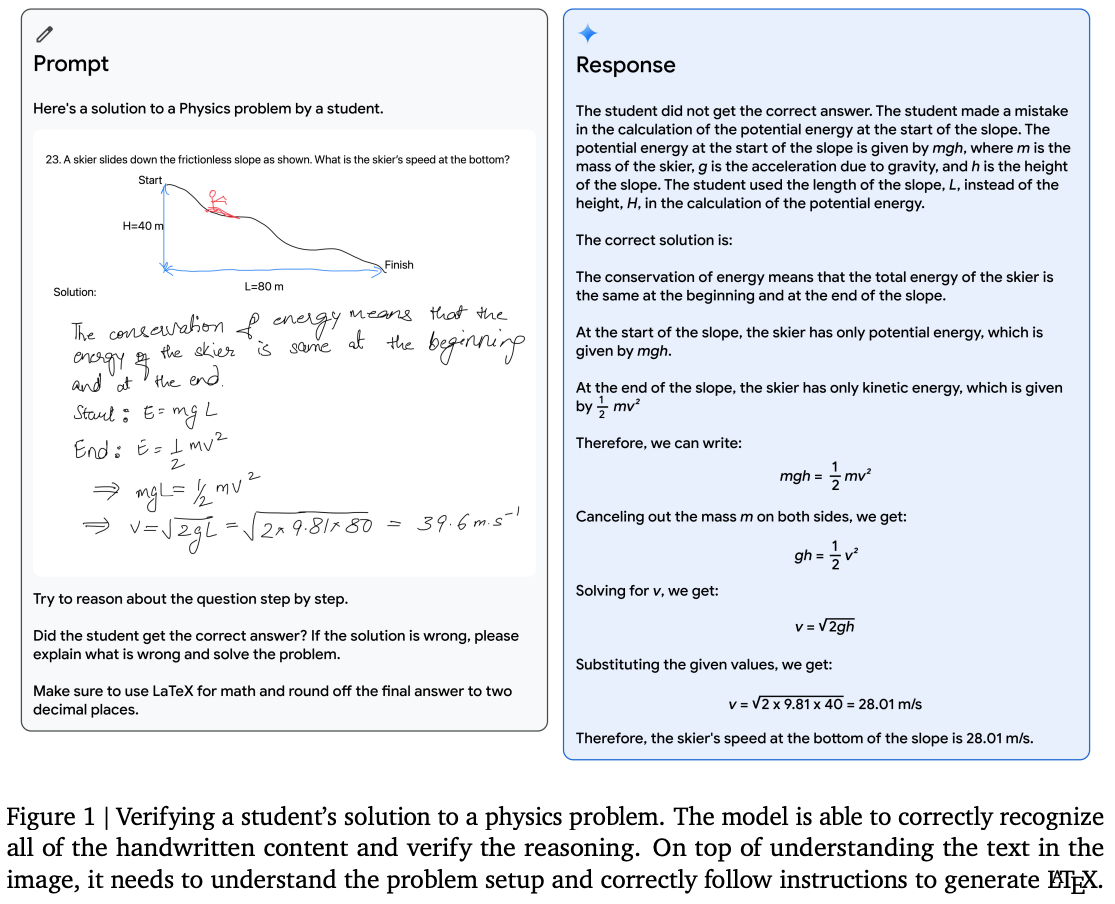
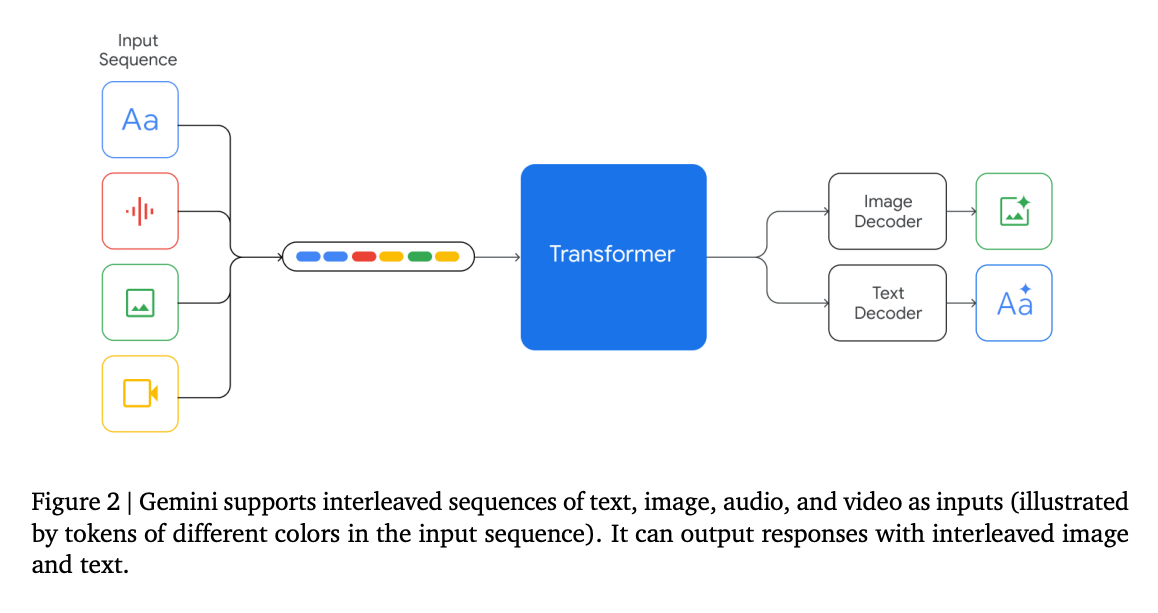
LLM Models
[Mixtral] Mixtral of Experts🔗
Arxiv: https://arxiv.org/abs/2401.04088 8 Jan 2024 Mixtral.ai
We introduce Mixtral 8x7B, a Sparse Mixture of Experts (SMoE) language model. Mixtral has the same architecture as Mistral 7B, with the difference that each layer is composed of 8 feedforward blocks (i.e. experts).
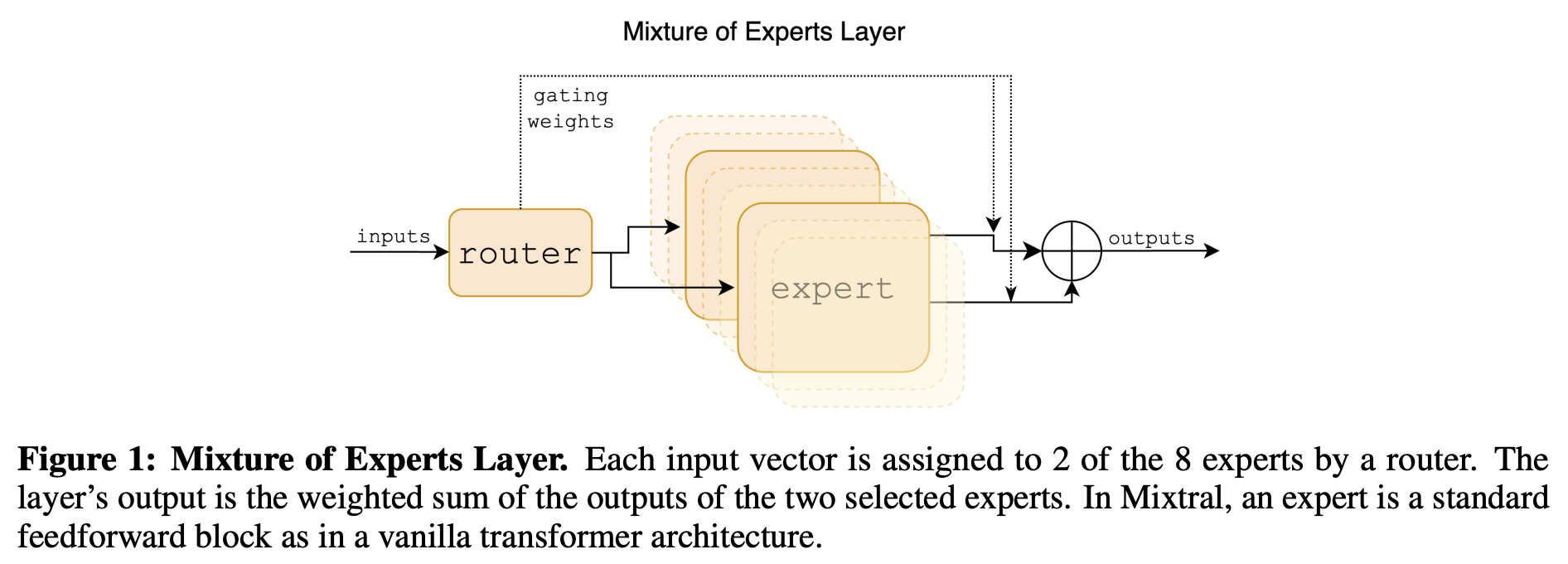
- G denotes n dimensionality of the gating network (router), E is the expert network.
Consecutive tokens are often assigned to the same experts. In fact, we observe some degree of positional locality in The Pile datasets. Table 5 shows the proportion of consecutive tokens that get the same expert assignments per domain and layer. Figures are not showing it clearly.

[Gemini] A Family of Highly Capable Multimodal Models🔗
Arxiv: https://arxiv.org/abs/2312.11805 19 Dec 2023 Google
The reasoning capabilities of large language models show promise toward building generalist agents that can tackle more complex multi-step problems.